

不少公司正在猶豫,是否應該擁抱人工智能的到來,原因在於他們擔心 AI 引擎,會將他們的專有數據,洩露給其他公司,尤其是競爭對手。但與此同時,有些公司卻有意將他們的數據,輸入到AI引擎中,將其作為品牌建設的重要一環。那麼,這究竟是一個價值數十億美元的商業機會,還是人工智能發展中的一大缺陷呢?
讓我們從頭開始瞭解。簡單來說,AI引擎有兩個組成部分。第一個是廣泛的內容數據庫,也被稱為大型語言模型(LLM),其中包含AI公司能夠找到的所有數據。例如,來自維基百科、紐約時報和其他公開可用的所有信息。
第二個組成部分是算法。算法利用LLM數據,來響應用戶提出的問題。如果我讓AI引擎來完成一句話,比如「狗在……跑」,算法會從LLM中檢索,查看這句話出現的次數,以及通常用什麼詞來完成這句話。然後,它會通過統計,給用戶提供最有可能出現的詞語。在這種情況下, 「馬路」而不是「鍋裡」,是通常情況下會出現的響應。
想要利用人工智能的公司,會從提出問題開始。例如,一家服裝公司可能會問「男士鞋最新的流行趨勢是什麼?」然而,僅僅通過提出這個問題,AI引擎就會知道,這家服裝公司正在考慮推出新款男士鞋,但這是該公司希望對競爭對手保密的信息。
在使用AI的各種方法中,有一種方法會產生尤為顯著的影響,那就是公司會上傳數據。比如上傳客戶反饋或歷史銷售數據,然後請求AI引擎找出對應的數據類型,並與LLM中的信息進行對比。然而,許多AI引擎將已經上傳的企業數據,添加到自己的LLM中,這樣當另一家公司提出同樣的問題時,就能生成一個透露這些數據的響應。儘管大多數AI公司,都出臺了政策和保護措施,來防止數據洩露的發生,但在最近的幾項研究中,60%~75%的公司已經禁止使用AI,因為他們認為這些保護措施尚不足夠。

世界知識產權組織(WIPO)的總幹事鄧鴻森認為:隨著人工智能技術的不斷進步,知識產權領域也將迎來新的變革。
在海南召開的博鼇亞洲論壇2024年年會上,鄧鴻森告訴記者「人工智能的存在是為了促進和支持人類創新,而不是取代或摧毀人類。」
近年來,在音樂、藝術、攝影和寫作等領域,人工智能侵犯版權的訴訟案件大幅增加。
鄧鴻森表示,知識產權體系,並不是第一次面對重大技術變革的衝擊。在上世紀90年代,隨著互聯網的興起和電子商務的出現,也曾出現過類似的情況。
「我認為人工智能不會從根本上改變知識產權體系」鄧鴻森說道。為了應對人工智能帶來的挑戰,WIPO與來自193個成員國的代表,定期舉行對話。此外,WIPO還頒佈了兩項政策法規,幫助各國和企業應對這一挑戰。
「我們期待與不同的合作夥伴合作,包括來自中國的合作夥伴,從而向中國的人工智能企業家提供支持,並利用中國的實踐,來幫助其他國家」他說。
1973年,中國政府派出了首批代表團,參加WIPO會議,並於1980年加入WIPO。去年是中國和世界知識產權組織合作的50周年。
成熟的生態系統
鄧鴻森表示,加入WIPO表明中國將創新和技術視為改革開放的重要內容。「在過去的50年裡,中國在知識產權領域,表現出了巨大的成長和進步。」
鄧鴻森表示,中國現在是世界上最大的知識產權申請國,申請內容涉及專利和商標,設計和地理標誌等各個領域。
2023年,中國提交了69610份專利合作條約(PCT)申請,是申請PCT最多的國家。鄧鴻森表示,其中大部分申請來自數字技術領域。去年,中國的電信巨頭華為技術公司,仍然是主要申請者,共有6494份公佈的PCT申請。
「我認為,中國在過去50年裡所取得的成就,包括從一個非常初級的階段,發展到現在擁有非常成熟的生態系統,並不是巧合或偶然」,而是因為中國一直高度重視知識產權」他補充說,WIPO很高興看到中國在這一領域所取得的發展。
在近期深圳和廣州的訪問中,鄧鴻森表示,中國企業越來越重視創新,並投入了大量資源進行研發。與此同時,地方政府還建立了「適宜的生態系統」,以鼓勵創新和創意。
鄧鴻森表示,隨著中國政府追求高質量發展,創新、技術和知識產權在下一階段的發展中,將變得更加重要。此外,中國還希望利用知識產權,來應對全球性挑戰,例如氣候變化,這有助於實現聯合國設定的可持續發展目標。

《數字市場法案》(D.M.A.),旨在限制網絡空間中,大型平臺作為「守門人」(指那些具有顯著市場地位和影響力的超大型數字平臺)的權力。法案實施後,歐盟委員會迅速採取行動,展開調查。
此次調查涉及谷歌應用商店的轉向規則、穀歌搜索的自營偏好問題,蘋果應用商店的轉向規則、 Safari 瀏覽器選擇屏幕,以及 Meta 的「付費或同意」模式等問題。
關於應用商店,人們普遍認為應用商店,會為其所有者帶來優勢和便利。因此,應用商店的運營策略,一直受到監管部門的關注。但其是否阻礙公平競爭,仍待證實。
除此之外,在Meta方面,用戶可通過購買無廣告服務,避免數據跟蹤和廣告推送。但隱私倡導者批評到,此舉強迫用戶為隱私付費。上周,Meta宣佈將套餐降價,以吸引更多用戶。
同時,歐盟委員會還宣佈,將對蘋果公司針對替代應用商店的新收費結構,以及亞馬遜在市場上的排名做法,進行初步審查。
歐盟的《數字市場法案》,旨在確保「守門人」平臺,能夠允許第三方在其平臺內進行交互,從而促進更廣泛的市場競爭。同時,還確保用戶和企業,能夠訪問平臺所提供的數據,並確保這些數據提供者的透明度和責任制。
此外,歐盟還發佈了在數字監管領域的另一法案——《數字服務法案》(D.S.A.),X和TikTok等也將受到審查。

上個月,美國科技公司OpenAI,推出了文本到視頻的生成模型Sora。此後,越來越多的中國公司,也開始著手開發輕量級大語言模型,為全球人工智能競爭格局,帶來了新變化。
輕量級模型,也被稱為較小的大型模型,指的是對參數需求更小的模型。這意味著它們相較於大型模型而言,處理和生成文本的能力會受到限制。
簡單來說,這些小的模型就像緊湊型汽車,而大模型則像運動型、多用途的豪華汽車。
今年二月,中國人工智能初創公司面壁智能(ModelBest Inc),推出了其最新的輕量級大語言模型,引起了人工智能行業的廣泛關注。
該模型名為MiniCPM-2B,參數規模為 20 億,遠小於OpenAI的GPT-4.0可以處理的1.7萬億參數。
去年十二月,美國科技巨頭微軟發佈了Phi-2,雖然參數規模僅為27億,但這款小型語言模型,能夠進行常識推理和語言理解。
面壁智能的CEO李大海表示「新模型在開源通用基準方面的性能,接近於法國人工智能公司Mistral的Mistral-7B,在中文、數學和編碼方面具有更強的能力。該模型的整體性能,超過了一些參數達到100億級別的同類大型模型。」
李大海還表示「不論是大型還是較小的大語言模型,都有各自的優勢,這取決於任務的具體要求,和它們的性能限制,但在人工智能蓬勃發展的環境中,中國公司可能會在小模型中找到一條出路。」
360集團創始人兼董事長周鴻禕,此前在接受採訪時也表示,要在當下打造出一個超越GPT-4.0的通用大模型,可能具有挑戰性。不過,雖然GPT-4.0目前「無所不知,但它並沒有深耕。」
他說「如果我們可以訓練出,具有特定行業數據的模型,並將其與行業內的其他工具整合起來,從而在該行業中取得卓越成績。這樣的模型不僅具備智能化,還將具備獨特的業務知識,從而變得無所不能。」
李大海表示,如果這樣的輕量級模型能夠應用於產業中,其商業價值將會巨大。他說「如果模型的參數規模被壓縮,運行時的計算過程就會減少,同時,這也意味著對處理器的性能要求會降低,並且響應時間也會縮短。隨著這類終端模型的普及,未來更多電子設備,如手機等,推理成本將會進一步降低。」
Instagram發佈了一些新的私信功能,旨在提高私信在APP裡面,所起到的關鍵連接作用。
根據Meta的觀察,用戶越來越不願意在Main Feed中發佈新內容,而是比較喜歡在私密聊天中,進行越來越多的互動。
所以為對應這些用戶行為,Instagram增加了消息編輯功能,你可以在消息發送後的15分鐘內編輯消息。這與WhatsApp去年新增的功能完全一樣。考慮到Meta的最終計劃,是將其所有消息工具合併為一個平臺,所以讓各個應用程序實現功能平衡,具有重要意義。
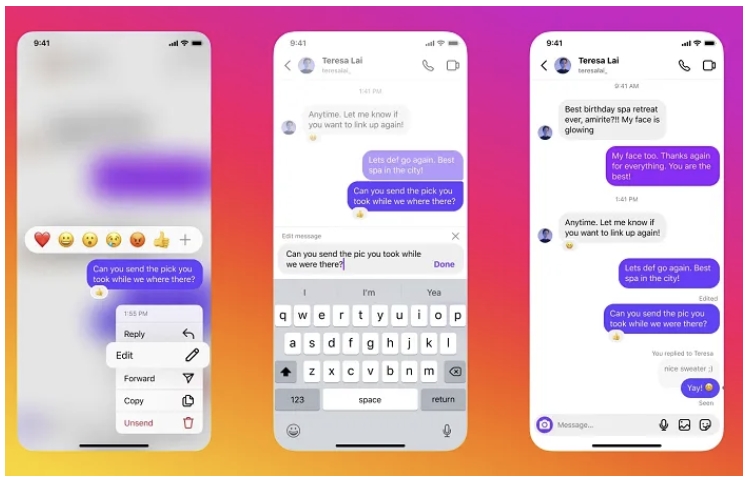
Instagram用戶,現在還可以在私信聊天框中,最多置頂三個聊天,從而能夠輕鬆地找到,他們認為最重要的聊天內容。
Instagram還增加了一項新功能,那就是可以啟用私信聊天的已讀回執功能,同時還添加了新的聊天主題,來個性化定制用戶的使用體驗。
最後,Instagram還在應用程序中,添加了有關貼紙的新選項,用戶可以保存自己喜歡的貼紙,保存的貼紙將置頂在貼紙框的頂部,從而更方便用戶在私信中使用。
這些功能變化與用戶的使用行為變化保持一致。不僅是Instagram,其他社交平臺也一樣,現在越來越多的用戶,更傾向於在私密的消息群組中分享內容,而不是發佈到Main Feed中。
2022年,面對用戶的擔憂——他們可能再也看不到自己關注的用戶,發佈新的內容。Instagram首席執行官Adam Mosseri給出了明確的回應「朋友將更多地通過Stories和私信分享動態,而不是通過Feed。」
Meta在近期平臺表現回顧中指出,現在人們在Instagram上看到的內容中,40%是通過AI推送的,這使得應用程序的使用時間,在過去一年中增加了6%。
儘管Main Feed中的帖子數量可能減少,但私信分享的內容卻大幅增加。Mosseri強調「現在人們分享內容和表達創造力的主要方式,是通過Instagram上的私信。在任何一天中,通過私信分享的圖片和視頻,都比在Stories和Feed中分享的多。」
因此,Stories現在僅次於私信,成為用戶之間互動的主要渠道,而Main Feed則更像TikTok那樣,側重於推送娛樂性質的內容。
這的確是值得關注的重要趨勢。在TikTok的引領下,Instagram正逐漸轉向由算法推動的互動,減少了對關注其他用戶的依賴,更加依賴系統向用戶推送可能感興趣的內容。

隨著生成式AI需求的爆發式增長,中國通信巨頭華為旗下的華為雲,亦正在開設新的數據中心,致力擴大全球影響力,希望吸引更多海外行業客戶。
在世界移動通信大會(Mobile World Congress 2024,簡稱MWC 2024)前夕,華為雲成功在巴塞羅納舉辦了一次雲峰會。華為高管在峰會上透露,公司計劃下月在埃及推出新的本地雲服務。目前,華為已在全球30個地區,設立了85個可用區。此外,高管還表示,華為還計劃在香港推出首個人工智能雲計算中心。
華為雲全球Marketing與銷售服務總裁石冀琳表示「在華為雲,人工智能是我們的關鍵戰略。我們正在為每個人、每個行業,構建一個堅實的雲基礎,以推動智能化的發展」。儘管ChatGPT等生成式AI服務,在中國市場備受歡迎,很多中國公司競相推出自己的大型語言模型(LLMs)。但華為堅持將自主研發的盤古人工智能模型,應用於工業領域。去年7月,華為發佈了盤古3.0版本,正式加入了中國雲服務市場的激烈競爭。華為一直在煤礦、鐵路等行業,積極推廣使用自主研發的AI模型。
華為一直在努力與傳統行業和企業,建立更深層次的聯繫,原因在於華為追求更多元化的收入來源,其在雲計算領域中的擴張正體現了這一點。
自2019年以來,美國對華為實施了多項制裁,並將其列入美國實體名單,切斷了華為與美國關鍵技術的聯繫,幾乎使華為在全球智能手機業務上取得的豐厚利潤遭受重創。但根據華為稱,在中國以外的區域,華為雲也取得了快速增長,2022年華為雲業務銷售額達到453億元。
華為輪值董事長胡厚崑,在去年12月的新年致辭中表示,華為雲業務在過去一年取得了穩步增長。根據市場研究機構Canalys的數據,華為已成為中國第二大雲服務提供商,並在全球範圍內不斷擴大其市場份額。去年,華為在土耳其和沙特阿拉伯,分別開設了新的數據中心,以進一步拓展其全球業務。

Google最近發佈了他們最新的AI模型Gemini 1.5,具備高達100萬token上下文窗口的“試驗性”功能。
Gemini 1.5的新功能,包括能夠輕鬆處理長達100萬token的文本段落,從而更深入地理解上下文及其含義。相比之下,之前的AI系統如Claude 2.1和GPT-4 Turbo,就有些相形見絀了,它們的token處理上限分別是20萬和12.8萬。
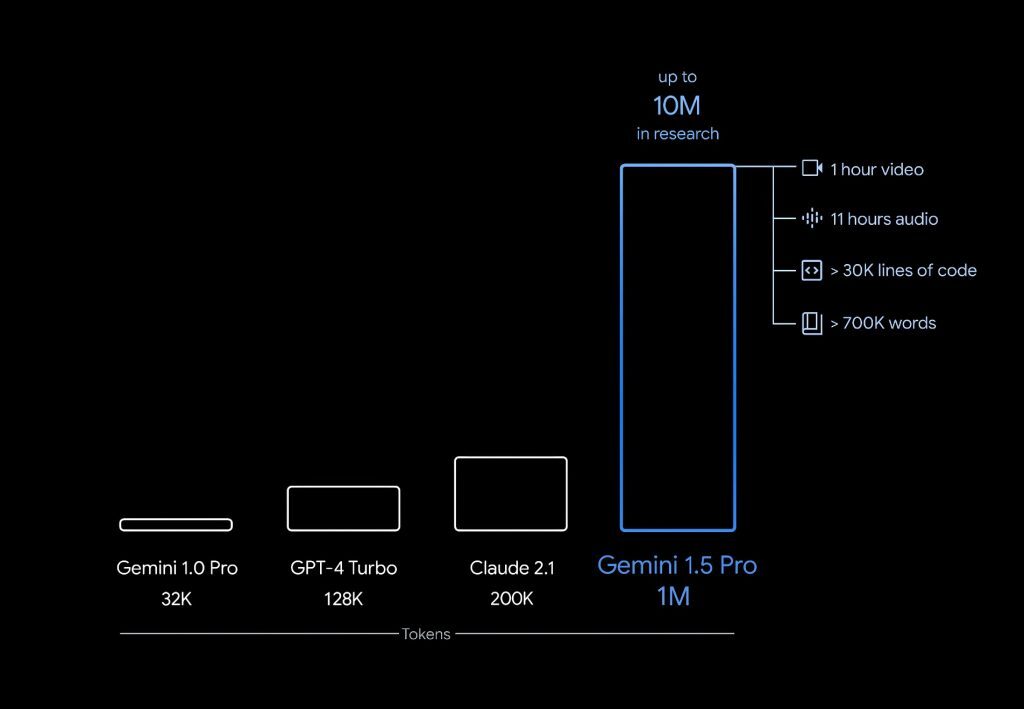
Google研究人員在一篇技術文檔中表示「Gemini 1.5 Pro在跨模式的長上下文檢索中,實現了近乎完美的回憶功能。這一突破不僅提升了長文檔QA、長視頻QA,和長上下文ASR的最新水平,還在一系列參數基準上,達到了或超越了Gemini 1.0 Ultra的先進水平。」
Google最新模型的效率提升,主要歸功於創新式的Mixture-of-Experts (MoE)架構。
Google DeepMind 的行政總裁 Demis Hassabis解釋說:「傳統的Transformer功能就像一個大型的神經網絡,而MoE模型則是被分解成更小的‘專家’神經網絡。」這種架構讓模型能夠根據輸入內容的類型,選擇性地激活與其最相關的專家路徑,從而極大地提高了模型的效率。
為了證明Gemini 1.5的強大功能,Google展示了其在處理阿波羅11號飛行記錄(包含32.6914萬token),和啞劇電影(包含68.4萬token)時的表現。在這些示例中,Gemini 1.5不僅能夠準確理解上下文,還能針對具體問題,給出精確的回答。
目前,Google正在向開發者和企業,提供免費的Gemini 1.5有限預覽版,其中包括100萬個token的上下文窗口功能。未來,這一功能將逐步向公眾開放,同時還將推出12.8萬個token版本,並公佈定價細節。
儘管100萬token的功能目前仍處於試驗階段,但如果Gemini 1.5能夠兌現其早期承諾的功能,那麼它有望成為AI理解現實世界中、複雜文本能力的新標杆。

2024年2月5日,第二屆全球人工智能倫理論壇 (the Second Global Forum on the Ethics of AI),在斯洛文尼亞的克拉尼市開幕。
這次為期兩天的論壇,由聯合國教科文組織主辦,彙聚了來自67個國家的政府代表、國際組織、學術研究機構、非政府組織和企業的600多名與會者,共同探討人工智能倫理的未來發展。
中國教育部副部長王嘉毅,在論壇上發表了意見。他表示,各國提出的人工智能治理計劃,體現了各自的實踐經驗,這為全球共識的達成,和共同治理計劃的制定,奠定了堅實基礎。中國願意傾聽各方意見,與全球夥伴開展深入的溝通、交流和務實合作,共同構建開放、公平、有效的人工智能治理機制,以推動這一技術更好地造福全人類。
此外,一名出席論壇的中國代表也表示,中國將積極參與全球人工智能倫理治理,致力於推動人工智能技術的健康發展,為全人類帶來福祉。
聯合國教科文組織負責社會和人文科學的助理總幹事,Gabriela Ramos在接受新華社採訪時表示,中國不僅制定了一系列措施和法律來監管人工智能,還積極參與國際社會,共同致力於解決AI技術可能帶來的負面影響,以期創造更加美好的科技未來。
![]()
Meta與Center for Open Science (COS) 宣佈建立新的合作夥伴關係,Meta將向COS的分析師,提供Facebook和Instagram平臺的參與度數據,這些數據經過篩選,並得到隱私保護。本次合作旨在推動與行為和參與度趨勢相關的研究。
跟據COS的介紹,「Meta與COS合作開展試點項目,Meta向COS的精英學術研究團隊,分享經過隱私保護的社交媒體數據,以研究人們的福祉。社交媒體公司如Meta有潛力為公共科學做出貢獻,幫助研究各種因素對福祉的影響,並為人們過上富足充實的生活,提供有益的信息。」
正如COS指出, 初步研究的核心問題,是用戶福祉、以及社交媒體對更廣泛的互動和行為趨勢的影響。
每個項目都將經過同行評審,研究人員需提交有關研究問題和方法的提案,並在數據收集階段開始之前,評估其可行性。
2018年的Cambridge Analytica數據洩露事件後,Meta加強了保障數據安全的措施,並暫停了幾乎所有研究項目。此前,Meta經常參與這類研究。
2018年,Cambridge Analytica將用於劍橋大學學術研究的Facebook數據,出售給政治團體,導致信息被濫用並影響選舉結果。這違反了用戶隱私協議,聯邦貿易委員會 (FTC) 對Meta處以高達50億美元的罰款,並要求其制定新的數據使用法規,和實施更多保護措施,以防止未來再次出現數據濫用現象。
Cambridge Analytica事件,促使Meta徹底改變數據隱私方法,並謹慎地與研究人員展開合作。
考慮到近一半的世界人口使用Meta公司的社交平臺,該公司在提供洞察力方面擁有巨大的價值,可以讓各個領域,在掌握更廣泛的事實的基礎上,取得新的進展。
因此,雖然採取保守的合作方式,但Meta希望能夠再次與更多學術團體合作。
最後,Meta與COS將開展為期兩年的試點項目,並將於未來幾個月,公佈更多合作細節,大家到時候不妨留意。

中國人工智能創業公司智譜AI,最近發佈了新一代基座大模型GLM-4。GLM-4的發佈,充分展示了智譜AI過去三年來取得的技術成果。
據智譜AI的CEO張鵬表示,GLM-4的整體性能得到了顯著提升,已接近OpenAI的GPT-4水平。其中值得關注的性能改善,主要包括,長文本處理能力提升,多模態理解能力增強,並實現更快的反應速度,和更高的實時性,從而大幅降低了推理成本。
此外,智譜AI還表示,GLMs的個性化智能體定制功能現已上線。利用GLM-4模型的強大功能,用戶可以通過簡單的提示詞指令,就能創建自己的GLM智能體,從而有效降低了大型模型的使用門檻。
與此同時,智普AI亦宣佈,已經啟動大型語言模型的開源基金。這一計劃包含全面的基金發放措施,主要包括向大型語言模型開源社區提供1000張AI芯片卡,向與大型語言模型相關的開源項目提供1000萬元現金支持。
其實,智普AI在於2019年成立,而他過去一年裡備受關注,主要因為去年6月,美國科技媒體The Information,將智普AI列為最有可能成為中國OpenAI的五家企業之一,所以今次發佈的GLM-4,勢必讓市場留意。