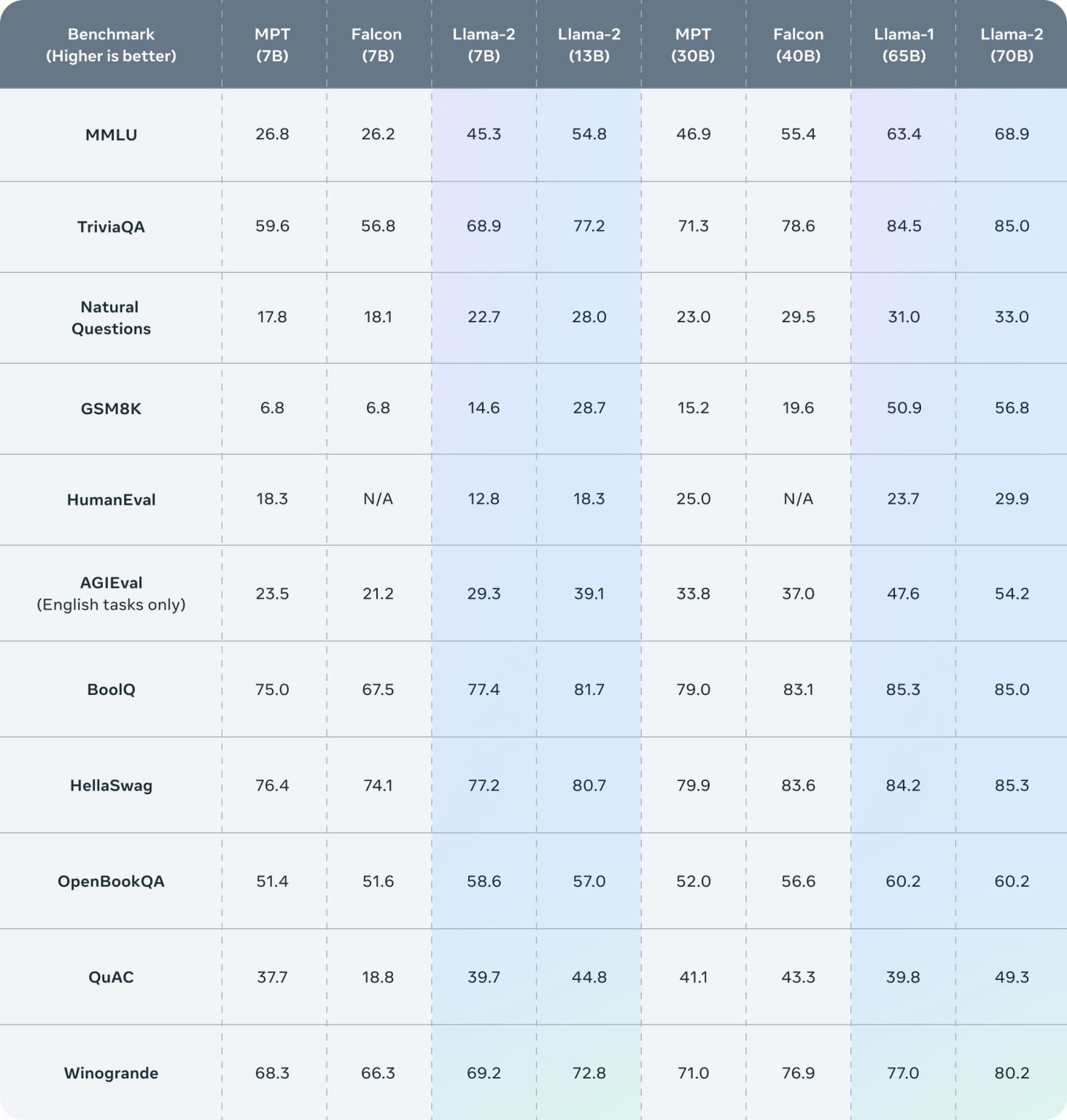
Meta 最近推出了一個開源的 AI 語言模型家族 Llama 2,並附帶一個許可證,允許將其整合到商業產品中。Llama 2 模型的大小範圍,從 70 億到 700 億個參數,使其成為 AI 領域的一支強大力量。根據 Meta 的聲明,這些模型「在我們測試的大部分基準上,超越了其他開源聊天模型。」
Llama 2 的發布,標誌著大型語言模型 (LLM) 市場的一個轉折點,引起了很多業界專家和愛好者的關注。市場的期盼,主要來源於 Llama 2 提供的兩種新語言模型變體 – 包括「已訓練模型」,和「微調模型」:
「已訓練模型」在兩萬億個標記上進行了訓練,並具有 4,096 個標記的上下文窗口,使其能夠一次處理大量內容。至於為像 ChatGPT 這樣的聊天應用設計的「微調模型」,已在「超過一百萬個人類註釋」上,進行了訓練,進一步提高了其語言處理能力。雖然 Llama 2 的性能,暫時可能還無法與 OpenAI 的 GPT-4 相媲美,但對於一個開源模型來說,也顯示出了其龐大的潛力。
Llama 2 的旅程,始於其前身 LLaMA,Meta 在二月份以非商業許可證的形式,將其發布為開源。然而,有人將 LLaMA 的權重洩漏到了種子網站,導致 AI 社區內的使用量激增。這為快速增長的地下 LLM 開發場景,奠定了基礎。
當然,像 Llama 2 一樣的開源 AI 模型,有其優點和疑慮。正面來說,它們鼓勵在訓練數據方面的透明度,促進經濟競爭,推進自由言論,並使 AI 普及化。然而,潛在的風險就包括,例如鼓勵垃圾郵件,或者不實信息的產生。
為了解決這些疑慮,Meta 發布了一份支持其開放創新方法的聲明,強調負責任和開放的創新,可以加強民眾對 AI 技術的透明度和信任。
儘管開源模型的好處顯而易見,但一些批評者仍然持懷疑態度,特別是認為用於 LLM 的訓練數據,缺乏透明度。另外,雖然 Meta 聲稱,已經努力去除包含個人信息的數據,但訓練數據的具體來源,由於仍然未公開,亦引發了大眾對隱私和道德考慮的疑慮。
無論如何,隨著開源開發和商業許可證的結合,Llama 2 可以為 AI 社區帶來令人期待的進步和機會,但同時也需要應對數據隱私,和負責任使用的挑戰。