

為了加速公司在人工智能(AI)領域的發展,Google 執行長 Sundar Pichai 最近宣布了一系列結構調整和領導層任命。
此次重組將由 Sissie Hsiao 領導的 Gemini 應用團隊併入 Google DeepMind,後者由 Demis Hassabis 領導。Pichai 解釋說:「將這些團隊緊密結合,能夠改善反饋循環,快速部署新模型,並提升我們在 Gemini 應用的開發效率,進一步強化產品的勢頭。」
此外,Assistant 團隊將專注於設備和家庭體驗,並整合至平台與設備部門,這一舉措旨在使這些團隊與它們所開發的產品更緊密對接,同時統一 Google 智能家居的 AI 戰略。
擁有 12 年 Google 工作經驗的 Prabhakar Raghavan,將從現任職位轉任 Google 首席技術官(Chief Technologist)。Pichai 表揚了 Raghavan 的領導能力,尤其是在 Gmail 團隊的領導下推出了「智能回覆」(Smart Reply)和「智能撰寫」(Smart Compose)等早期 AI 應用,成功將 Gmail 和 Google Drive 用戶數提升至十億人次以上。
K&I(知識與信息)部門將由 Google 長期員工 Nick Fox 接管,他曾參與多個產品領域的開發,包括搜尋、Assistant、購物、旅遊及支付產品。Pichai 表示,Fox 在制定 Google AI 產品路線圖上發揮了關鍵作用,並經常承擔公司最具挑戰性的產品問題。
此次重組正值 Google 在 AI 領域推出多項創新之際,這些創新包括 NotebookLM 的音頻概要(Audio Overviews)、搜尋和 Lens 的信息發現功能增強、新版 Google 購物平台的推出,以及新的 Gemini 模型家族的進展。此外,Google 在醫療 AI 領域也取得了重要里程碑,其糖尿病視網膜病變檢測系統已在印度和泰國完成了 60 萬次篩查。
Pichai 強調:「AI 的發展速度遠超以往任何科技。為了保持這種發展勢頭,我們正進行結構簡化,以加快進展。」

YouTube最近宣布了一系列新功能,包括更新頻道會員徽章、付費產品置入選項,並對Shorts(短片)草稿的呈現方式進行了變更。
首先,YouTube澄清了有關Shorts的變更。YouTube此前宣佈,所有長度在三分鐘以內的影片都將歸類為Shorts,這引發了不少創作者的困惑。為此,YouTube進一步解釋說:「2024年10月15日前上傳的3分鐘或更短的垂直影片仍將保持為VOD(隨選視訊)或長篇影片。不會自動將之前上傳的影片轉為Shorts,只有在今日之後上傳的0至3分鐘的方形或更高比例的影片才會被視為Shorts。」
這意味著,過去上傳的影片不會受到影響,只有新的短片上傳才會被標記為Shorts。YouTube還指出,系統需要數週時間來適應這一變更,因此,如果創作者上傳超過60秒的影片,它仍會暫時顯示為長篇影片,並可進行推薦。未來幾週內,這些影片將逐漸轉為Shorts,並顯示在頻道頁面的Shorts標籤下。
此外,YouTube還允許創作者在YouTube應用中更改Shorts的縮略圖畫面,並在Studio桌面和移動版中擴展了自定義會員徽章的上傳功能。創作者現在可以在上傳過程中更輕鬆地添加會員徽章和表情符號。
在贊助內容標籤方面,YouTube也做出了改進。創作者無論是在移動端還是網頁端,現在都可以更方便地標註短片或長片為贊助內容。此外,YouTube還擴展了Shorts草稿功能,允許創作者在Android和iOS平台上查看、編輯或刪除多個草稿。
這些更新雖然不大,但都為創作者提供了更靈活的管理工具,無論是在桌面端還是移動端,都能更好地管理內容。

根據SponsorUnited發佈的最新研究,新興品牌正積極尋求與網紅(influencers)及名人(celebrities)合作進行代言活動。在過去12個月內,進入代言市場的品牌中,有29%是首次參與此類合作。然而,這些新進品牌中,僅4%進行了多次代言合作,大多數品牌選擇僅與一位名人或網紅合作。
首次參與代言合作的品牌主要來自消費品、食品和服裝配飾類別,這三大類別佔所有新進品牌的38%。SponsorUnited的《2024名人與網紅報告》分析了650多個品牌和1350筆代言合作,並評估了2023年9月3日至2024年9月2日間發布的3000篇名人和網紅相關的社交媒體帖文。
在整體代言市場中,化妝品和護膚品牌是最活躍的參與者,擁有68份代言合作,成為最大的分類。緊隨其後的是非運動類服裝和鞋類品牌,擁有62份代言合作。L’Oréal(歐萊雅)和沃爾瑪(Walmart)各自擁有六個代言合作,成為代言市場的領導品牌;亞馬遜Prime(Amazon Prime)和Airbnb則各自擁有五個代言合作,緊隨其後。
傳統名人依然擁有很強的影響力,但網紅的影響力正在增長。報告顯示,過去12個月內,全球前100名名人和網紅的新增粉絲數達到9.18億,其中超過70%的粉絲增長來自於網紅。這一趨勢主要受益於YouTube的影響。知名網紅Jimmy “MrBeast” Donaldson的粉絲數在過去一年增加了1.82億,使他成為增長最快的網紅。而在名人中,意大利體育記者Fabrizio Romano的粉絲增長最多,達到2200萬。
在這些代言合作中,年齡在25至44歲之間的名人和網紅最為成功,這一年齡段佔據了總代言數的58%。性別方面,男女代言合作數量相對平均,女性佔48%,男性佔52%。在平台受歡迎程度上,名人的粉絲主要來自Instagram(61%),而網紅的粉絲則集中於視頻平台,特別是TikTok(36%)和YouTube(34%)。
該研究表明,名人和網紅的代言合作已成為品牌推廣的重要策略,尤其是網紅在YouTube和TikTok等視頻平台上的影響力迅速增長。香港特區政府應考慮推動本地品牌與網紅合作,尤其是在視頻平台上,從而提升品牌知名度和國際影響力,促進本地及國際市場的品牌發展。

Galileo,作為業界領先的企業級生成式AI解決方案供應商,近日發佈了最新的 「幻覺指數」(Hallucination Index)。
本次評估框架,聚焦于檢索增強生成(RAG)技術,對OpenAI、Anthropic、Google及Meta等在內的22個主流生成式AI大型語言模型(LLM),進行了全面剖析。與去年相比,今年的「幻覺指數」顯著擴容,新增了11個模型,反映出了過去八個月間,開源與閉源LLM領域的蓬勃發展與快速增長態勢。
Galileo CEO兼聯合創始人Vikram Chatterji指出「在日新月異的AI領域,開發者與企業正面臨一項重大挑戰:如何有效利用生成式AI的強大功能,同時兼顧成本效益、精准度與可靠性。遺憾的是,當前的評估基準多以學術場景為基礎,而非現實世界的應用需求。」
Galileo採用的「幻覺指數」,引入了上下文依從性(context adherence)這一核心評估指標,該指標通過檢驗模型在不同輸入長度(從1,000到100,000個上下文詞匯)下,所出現的輸出不準確性。此評估方法旨在為企業提供寶貴的洞見,助力其在AI部署過程中,就成本效益與性能表現之間,做出更加明智的權衡決策。
該指數的主要發現成果包括:
- Anthropic的Claude 3.5 Sonnet整體表現最佳,無論是在短、中還是長文本場景中,都表現穩定,近乎完美。
- Google 的 Gemini 1.5 Flash 在成本效益方面表現最佳,在各類任務中表現優異。
- 阿裡巴巴 的 通義千問Qwen2-72B-Instruct, 以表現最佳的開源模型脫穎而出,特別是在短至中長度文本場景中,表現卓越。
該指數還揭示了LLM領域的幾大顯著趨勢:
- 開源模型正在快速縮小與閉源模型間的差距,以更低的成本提供優化的「幻覺」處理能力。
- 當前的 RAG LLM ,在處理擴展上下文長度方面,得到了顯著改進,不僅保持了高質量輸出,還確保了準確性。
- 輕量模型憑藉高效設計策略,在某些場景下反而能超越大型模型,證明了在LLM領域,智慧設計往往比單純追求規模更為重要。
- 值得注意的是,來自美國以外的優秀競爭者,如Mistral的Mistral-large及阿裡巴巴的Qwen2-72B-Instruct等,紛紛嶄露頭角,彰顯了全球範圍內LLM開發競爭的日益白熱化。
結語
隨著AI行業不斷努力攻克生成式AI產品中出現的幻覺問題,Galileo推出的「幻覺指數」,能夠讓企業在特定需求與預算的限制下,找到合適的模型,為他們提供極具價值的指引與洞見。同時,還反映出技術的發展不僅僅依賴於規模,更強調設計的智慧和成本效益的平衡。此外,全球範圍內的競爭加劇,也意味著未來會有更多創新和優化的AI模型湧現。

- 科大訊飛將斥資4億港元,在數碼港組建一支150人的研發團隊
中國人工智能先鋒企業科大訊飛,7月19日宣佈,將在未來五年內向香港投資4億港元(約合5120萬美元),並已在香港設立國際總部。
在深圳上市的科大訊飛,以其語音識別技術而聞名,其子公司訊飛醫療,已搬入位於數碼港的新辦公室。數碼港坐落在香港南區,是由政府扶持的科技中心。
科大訊飛宣佈,此次投資計劃組建一支150人的研發團隊,專攻大型語言模型(LLMs)及智能語音、教育、醫療領域的AI應用,LLMs是生成式AI服務(如ChatGPT)的核心技術。
科大訊飛副總裁段大為,在新辦公室開幕儀式上透露「我們初期預算設為4億港元,如果香港業務進展順利,預算將會追加。」
段大為稱,隨著新國際總部的成立,科大訊飛計劃將其旗艦產品Spark大型語言模型及語音識別技術,全面推廣至香港企業及本地消費者。
科大訊飛,源自安徽合肥,已成立25年,正計劃與本地公司(如教育和醫療行業的公司)展開合作,共建計算基礎設施,並依託其大型語言模型,定制開發AI應用。
段大為補充道,香港特區立法會已經採用了科大訊飛的實時語音轉文字工具,進行會議記錄。香港還將作為科大訊飛智能教育硬件和服務,走向海外市場的起點,重點瞄準中東和東南亞市場。
科大訊飛此舉強化了香港政府打造科技創新中心的雄心。
2023年8月,香港特區行政長官李家超承諾,將於2035年前建成跨境科技中心,凸顯香港作為內地聯通世界的橋樑地位。
香港特區創新科技及工業局局長孫東,在數碼港的開幕儀式上表示「政府一直大力支持香港創新科技的發展,重點關注AI和生命健康科技。」
即便2019年科大訊飛遭美國列入貿易黑名單,但公司運營仍然蓬勃發展,並加大了對核心AI項目的投入力度。
上個月,科大訊飛透露,其大型語言模型,已完全在其與華為聯合打造的國內計算平臺上,完成訓練,旨在助力中國實現科技自主,並應對美國制裁。
數碼港行政總裁鄭松岩表示「數碼港正在建設一個包括超級計算中心在內的AI生態系統。」他表示,儘管與百度公司的討論已經開始,但科大訊飛也將參與其中。
與此同時,訊飛醫療,計劃設立一個融合健康科技和人工智能的國際研究院。今年1月,科大訊飛透露,計劃在香港為其醫療子公司,進行首次公開募股。
科大訊飛,宣佈在未來五年內向香港投資4億港元,成立國際總部,並組建150人的研發團隊,專注於大型語言模型,及智能語音、教育和醫療領域的AI應用。
此舉旨在推廣其核心技術至香港市場,並借助香港作為跳板,拓展至中東和東南亞市場。同時,也顯示了香港作為科技創新中心的潛力,強化了我們作為內地與國際市場之間橋樑的角色。香港政府對創新科技的支持,包括AI和生命健康科技,吸引了更多企業加大在港投入,定必助力香港實現成為跨境科技中心的目標。

近年來,人工智能不僅在科技領域掀起創新熱潮,食品行業也在這一火熱趨勢中,投入了大量資金。
美國消費者在光顧超市及心儀快餐店時,已經注意到了新技術的引用,包括自助結帳機,和得來速通道的AI點餐服務。
在食品價格不斷攀升的當下,美國消費者正積極尋求各類優惠,並相應地調整消費習慣。面對競爭壓力,食品行業正大力投資人工智能領域,以期削減高昂的人力成本,並降低部分商品的價格。
例如,麥當勞、Taco Bell和Wendy’s等快餐連鎖店,重新推出了優惠菜單。而大型零售商如沃爾瑪和Target,則降低了一些食品的價格。
「在當前環境下,想要實現高利潤、高銷售額,並保持客戶滿意度,是非常困難的,」GlobalData的總經理和零售分析師Neil Saunders說道。「這是一個很難達到平衡的方程式。我認為,如果經濟形勢不發生變化,那麼這個平衡將難以真正實現。這就是現實。」
面對當前嚴峻的經濟形勢,麥當勞在今年宣佈了一項計劃,將斥資20億美元在其餐廳和得來速通道,引入人工智能與機器人技術。而根據食品行業協會(FMI)的研究,2022年,超市行業在技術自動化領域的投入,已高達130億美元。FMI預測,至2025年,如智能購物車、優化升級的自助結帳通道等創新技術的投入,將激增400%。
「未來幾年,我們將看到很多積極方面,人工智能和技術能夠增強客戶體驗,同時簡化團隊成員的工作,」Yum Brands的首席數字與技術官Joe Park說道。
想要瞭解食品行業如何利用人工智能重塑客戶體驗,請觀看本視頻。

阿裡雲與競爭對手,紛紛將目光投向今年預期增速更猛的市場。這一趨勢轉變,部分歸因於生成式AI的盛行。
7月8日,阿裡巴巴集團旗下的阿裡雲,啟動了一項新的廣告宣傳活動。廣告中出現了兩位新晉「代言人」,分別是初創公司月之暗面(Moonshot AI)的創始人,和智聯招聘的集團總裁。
新系列代言廣告,目前在首都機場和杭州機場進行展示。標語「我用的雲是阿裡雲」 響亮登場,彰顯阿裡雲作為業界先鋒,支持人工智能開發的卓越能力。
廣告中,中國「新AI猛虎」月之暗面創始人楊植麟,盛讚阿裡雲,稱其「強大計算能力」與「大模型服務平臺」顯著提升了Kimi模型的效率。
阿裡巴巴作為月之暗面的重要後盾,斥資約8億美元收購了其36%的股權。去年十月亮相的Kimi聊天機器人,由月之暗面自主研發的模型提供驅動,並被寄予厚望,視為中國對OpenAI ChatGPT的有力回應之一。
另一則廣告中,智聯招聘集團總裁張月佳,對阿裡雲讚譽有加,稱其幫助公司在人力資源應用中,迅速採用大型AI模型。
放眼市場,自去年起,中國雲計算市場硝煙四起,各大巨頭競相降價,以爭奪從大型企業到中小型企業的客戶。

歐盟加大了對AI交易領域的反壟斷審查力度,首要目標是調查微軟與OpenAI、及谷歌與三星之間,引人注目的合作。
歐盟委員會執行副主席兼競爭專員Margrethe Vestager,此前警告稱,「AI正在以驚人的速度發展」,並透露正在對各種與AI相關的市場行為,進行初步調查。她對潛在反競爭行為的憂慮,主要源自ChatGPT橫空出世後,主流科技公司在AI領域內採取的一系列舉措。
委員會的行動表明,在迅速發展的AI領域,歐盟日益關注科技巨頭可能形成的壟斷力量。審查的重點,包括近期在AI領域中,微軟和谷歌達成的交易和合作。這些操作行為通常涉及到戰略合作和收購,並引起了監管機構的關注。原因在於這些行為可能會削弱競爭、有損創新。
儘管並未透露具體細節,Vestager強調,委員會目前正在對AI相關市場內的各種行為,進行多項初步反壟斷調查。
微軟與OpenAI的合作夥伴關係
微軟與OpenAI建立的數十億美元合作,堪稱AI領域的標誌性聯盟。從2019年開始,該合作不斷深化,微軟不僅鉅資注入OpenAI,還依託Azure雲提供強大算力支持,並將OpenAI的前沿技術,無縫融入自身產品服務中。
該合作旨在加速對AI的研究和開發,成果斐然,如GPT-3以及最新版本的ChatGPT。然而,這一聯盟引發了有關市場主導地位,和小型AI企業准入障礙的擔憂。Vestager在演講中表示,歐盟委員會,去年開始審查該交易是否違反了歐盟《合併規則》,但終因認定微軟未掌控OpenAI而暫停調查。
「多年來,微軟已向OpenAI投資了130億美元。但我們必須確保這樣的合作夥伴關係,不會成為一方對另一方施加控制性影響的偽裝」她表示,同時暗示委員會將採取另一種方式,來審查該交易及整個行業。委員會正在使用歐盟的反壟斷法規,嚴控市場領頭羊的濫用行為。
另一個焦點:谷歌與三星的合作
谷歌與三星的AI相關合作,也引起了重大關注。該合作利用三星的硬件能力和穀歌的AI技術,開發出具有創新性的消費電子產品和移動技術。其中包括將穀歌的AI算法整合到三星設備中,優化語音識別、相機功能,和個性化用戶體驗等特性。
雖然這一合作,有望為廣大消費者帶來先進的、由AI驅動的性能,但也引發了關於競爭公平性的質疑,特別是對於關鍵技術的訪問和市場影響力。Vestager表示,歐盟監管機構已發出信息請求,旨在深入瞭解谷歌與三星的合作,特別是Gemini Nano(穀歌Gemini AI基礎模型精簡版)在三星設備上的預裝情況及其市場影響。
接下來會如何發展?
隨著微軟、穀歌等科技巨頭,在全球AI領域通過收購與合作,不斷擴張其影響力,監管機構對市場主導地位的關注日益加深,擔憂其對公平競爭造成的潛在影響。這一趨勢,預示著歐盟未來必將加強監管和干預。
對此,微軟與谷歌重申了將嚴格遵守監管規定的承諾,並堅持在AI技術領域內,負責任地推進創新。兩家公司共同強調了其AI計劃所帶來的潛在益處,特別是在醫療保健、可持續發展,及其他關鍵領域的積極進展。
然而,歐盟的反壟斷審查結果,或將深刻影響主要科技公司,在歐洲AI市場的運營格局。此舉或催生一系列監管措施,旨在構建一個更加公平的競爭環境,確保小型競爭對手也能享有平等的競爭與創新機遇。

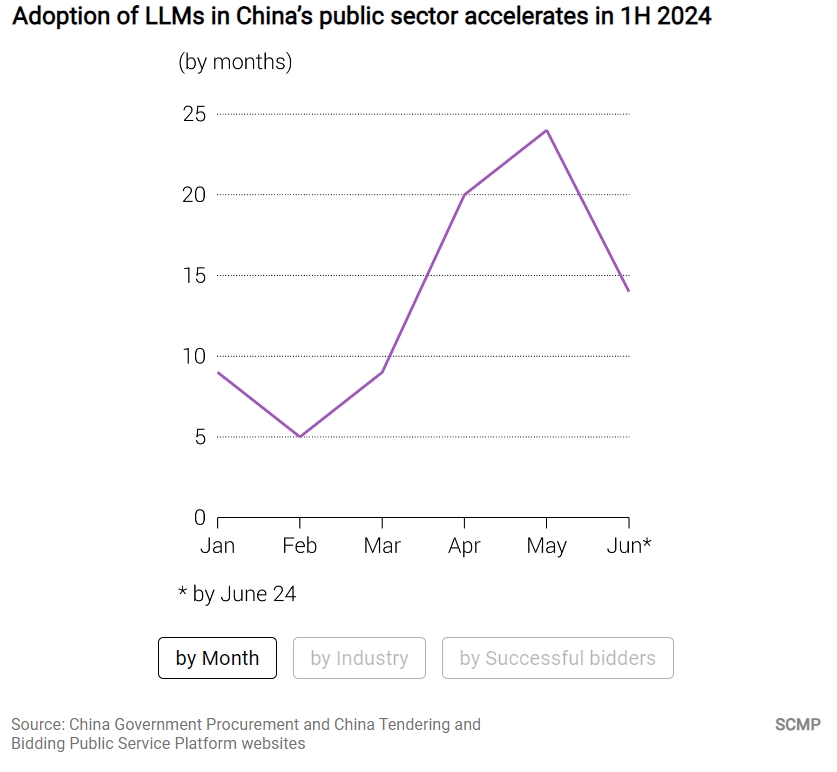
- 2024年上半年,有81個涉及使用大型語言模型(LLM)的公共項目,競標成功。而去年同期,僅有一個項目成功競標。
政府數據顯示,今年以來,中國大型企業加快了採用人工智能的步伐。上半年,相關項目的合同數量激增。根據中國政府採購網和中國招標投標公共服務平臺,網站上公佈的數據,從第一到第二季度,涉及使用LLM的招標合同數量,大幅增長——前三個月為23個,4月至6月24日為58個。這些合同都使用了「大模型」這個關鍵詞。
LLM技術是一種支持對話式的人工智能機器人,如OpenAI的ChatGPT。2022年底,由微軟支持的OpenAI,推出廣受歡迎的聊天機器人。自此,中國的科技公司,也競相推出數百種自主研發的LLM,以及以LLM為運行基礎的產品。網站顯示,2023年上半年,與LLM相關的招標合同僅有一個,而在去年的第四季度,這個數字有所增加。
由於只有涉及公共利益和安全、公共資金或外國公司貸款的項目,才需要公開披露,因此這些合同反映了中國大型企業的業務重心。百度、華為、騰訊等科技巨頭,以及一些資金充足的初創公司,在上半年都成功中標。
這些數字可以讓人們初步瞭解AI在中國日益發展的情況、誰在這一領域取得了最大進展,以及這些技術應用於哪些行業。
能源、電信、金融和科研等相關部門,最希望能夠利用LLM的潛力。這些行業所涉及的項目數量分別是19、14、12和10個。
北京某區的環境保護部門,購買並定制了LLM,來幫助他們預測洪水情況。中國核動力研究設計院和中國招商證券,利用智譜AI(總部位於北京的初創公司)所開發的LLM,從其多年運營所積累的素材中,提煉出知識和技巧,從而促進員工的工作便利。
中國能源巨頭,正運用LLM來發現電網和石油勘探設備的潛在問題。
中標最多的並不是中國的傳統互聯網巨頭,而是被譽為「中國AI四虎」的智譜AI。今年,與LLM相關的競標合同中,智譜AI中標最多,達12個。以語音識別技術著稱的科大訊飛,成功中標了10個合同,這些合同主要來自國有企業和政府機構。百度和華為分別中標了五個和三個合同。
從月度來看,第二季度LLM合同招標的速度顯著加快。一月、二月和三月分別有9個、5個和9個合同,成功中標。四月,這一數字躍升至20個,五月為24個,六月則有14個。此外,81個合同的總價值為人民幣4.33億元,平均每個合同約530萬元。

計算機視覺和模式識別(CVPR)大會,於6月17日至21日在美國西雅圖舉行。NVIDIA研究人員在大會上,展示了最新的視覺生成AI模型和技術。這些研究成果包括定制圖像生成、3D場景編輯、視覺語言理解,和自動駕駛感知等領域。
「人工智能,尤其是生成式AI,代表了一項關鍵的技術進步。在CVPR大會上,NVIDIA 研究部門展示了我們是如何突破極限的——包括為專業創作者提供強大助力的圖像生成模型,和幫助實現下一代自動駕駛汽車的自動駕駛系統。」NVIDIA學習和感知研究部門的副總裁Jan Kautz說。
在50多個NVIDIA研究項目中,有兩篇論文入選CVPR最佳論文獎候選名單——其中一篇探索了擴散模型的訓練動態,另一篇則探討了自動駕駛汽車的高清地圖。
此外,NVIDIA在CVPR自主駕駛大獎賽的“規模化端到端駕駛”比賽中勝出,從全球450多個參賽項目中脫穎而出。這一里程碑式的成果,展示了NVIDIA在使用生成式AI,進行綜合自動駕駛車輛模型方面,所進行的開創性工作,並由此獲得了CVPR的創新獎。
其中一個研究亮點是JeDi 技術。JeDi 是一項允許創作者快速定制擴散模型的新技術——這種方法是目前文本生成圖像的主流方式。無需在自定義數據集上耗時地微調,只需使用少量的參考圖像,JeDi就可以呈現特定的圖像或角色。
另一項突破性技術是FoundationPose 模型。這是一種新的基礎模型,能夠在不進行逐個對象訓練的情況下,瞬間理解和追蹤視頻中物體的3D姿態。這項技術打破了性能的新記錄,並有望解鎖新的增強現實(AR)和機器人應用。
NVIDIA研究人員還介紹了NeRFDeformer。這將簡化使用單個RGB-D圖像轉換NeRFs的過程,以及簡化將捕獲的2D圖像更新為3D場景的過程。
在視覺語言方面,NVIDIA與麻省理工學院(MIT)合作開發了VILA。這是一系列新的視覺語言模型,在理解圖像、視頻和文本方面,達到了業界領先水平。憑藉推理能力的提升,VILA甚至可以通過結合視覺和語言理解,來解讀網絡圖梗。
NVIDIA的視覺AI研究跨越多個行業,其中十多篇論文探討了自動駕駛感知、導航和規劃的新方法。NVIDIA的AI研究團隊副總裁Sanja Fidler展示了視覺語言模型在自動駕駛汽車領域中的潛力。
NVIDIA在CVPR大会上所呈现的廣泛研究,展示了生成式AI能够賦能創作者,加速製造業和醫療保健的自動化,同時推動機器人技術的發展。